
Introduction
To increase uptime, it is normal to utilize multiple resources that serve identical functions within your on-premise and/or cloud environment. Examples include several web servers or entire multi-tier architectures including web servers, databases, and static data storage; this is a standard practice. However, the challenge arises in ensuring the operational efficiency of a portion of your infrastructure and being prepared to redirect traffic to an alternative location in the event of a failure. This is precisely the role fulfilled by Amazon Route 53 DNS health checks and failover mechanisms.
In this blog post, I will delve into the health-checking capabilities of Route 53 and demonstrate how to direct traffic exclusively to AWS resources that are verified to be in good health; however the capabilities can be used for any endpoint and their respective locations.
What is Amazon Route 53 Health Check
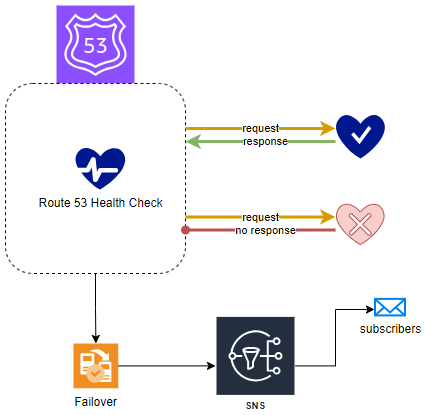
Route 53 health checks are designed to monitor the status of specific AWS resources or any endpoints capable of responding to requests. These checks not only send notifications (e.g. via SNS) upon any status change but also enable Route 53 to identify and reroute traffic away from resources that are not functioning optimally (e.g. failover).
Types of Route 53 Health Checks
Currently, three distinct types of Route 53 health checks are offered:
- Endpoint Health Checks
- This is the most frequently utilized type, allowing for the monitoring of an endpoint specified by either an IP address or a domain name. Route 53 periodically sends automated requests to your application, server, or other resources to ensure they are accessible and functioning correctly.
- Health Checks Monitoring Other Health Checks
- In this setup, a “parent” health check oversees the status of one or more “child” health checks. If the children maintain a healthy status beyond a predetermined threshold, the parent check is also considered healthy. Conversely, if too many child checks fail, the parent check is deemed unhealthy
- Health Checks for Amazon CloudWatch Alarms
- These health checks are tied to alarms set in the CloudWatch service, monitoring CloudWatch data streams linked to these alarms. If the CloudWatch alarm status is OK, the health check will also report as OK.
Amazon Route 53 DNS Failover Routing
Failover routing in Route 53 enables the redirection of traffic from a primary region to a recovery region (or even intra-region) in case of failure. By setting up endpoints in both the primary and recovery regions under a single domain name, you can select a routing policy that determines the recipient of traffic for that domain. Traffic is automatically rerouted to the recovery area if the primary server is deemed unhealthy by the health checks.
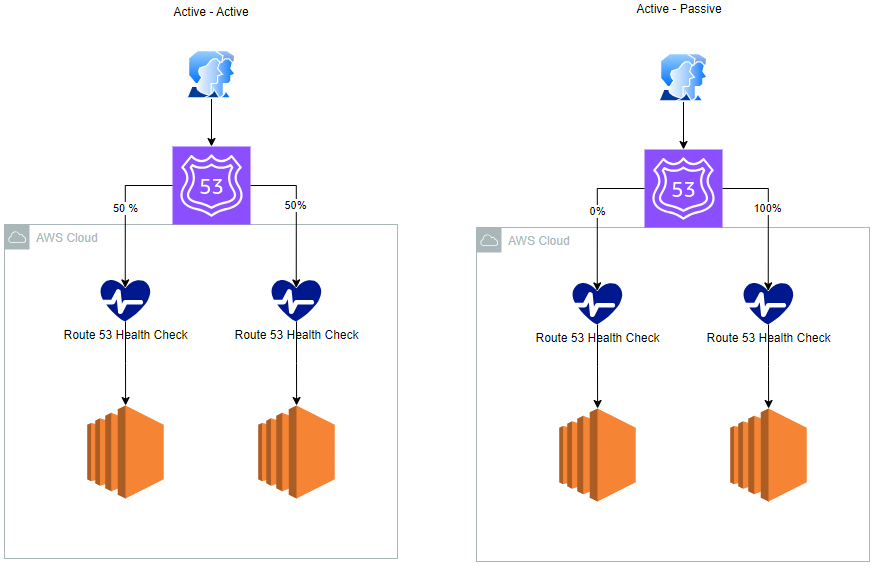
Active-Passive versus Active-Active Failover
The key distinction between these architectures lies in their operational status. Active-active failover allows all resources across all regions to be accessible concurrently, making it ideal for scenarios where resource availability is a priority. In contrast, active-passive failover involves a primary resource or set of resources being actively available, with a secondary set on standby to take over in the event of a primary failure.
- Active-Active Failover
- This approach ensures that resources in both regions 1 and 2 are always active and requests are sent to both evenly. Route 53 is capable of detecting unhealthy resources and excluding them from query responses, thereby maintaining continuous operation.
- Active-Passive Failover
- This configuration is suitable when you prefer a primary resource or set of resources to be predominantly active, with a secondary set reserved for activation only upon the failure of the primary resources.
Demonstration
Logical
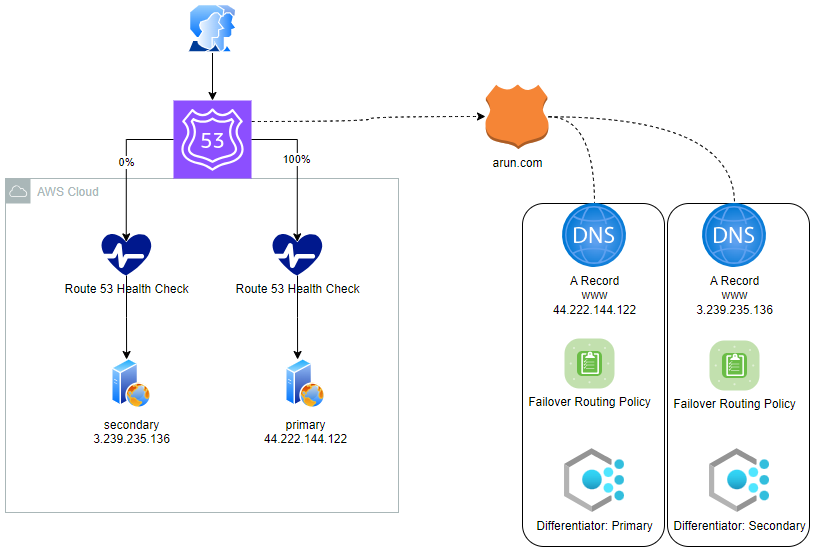
Players
- EC2 in one zone with apache running with public access to http – Primary
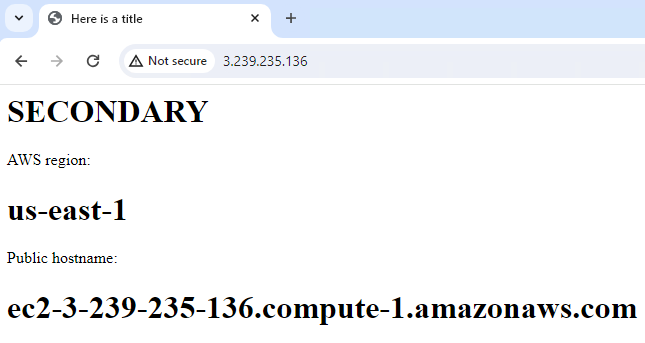
- EC2 in one zone with apache running with public access to http – Secondary
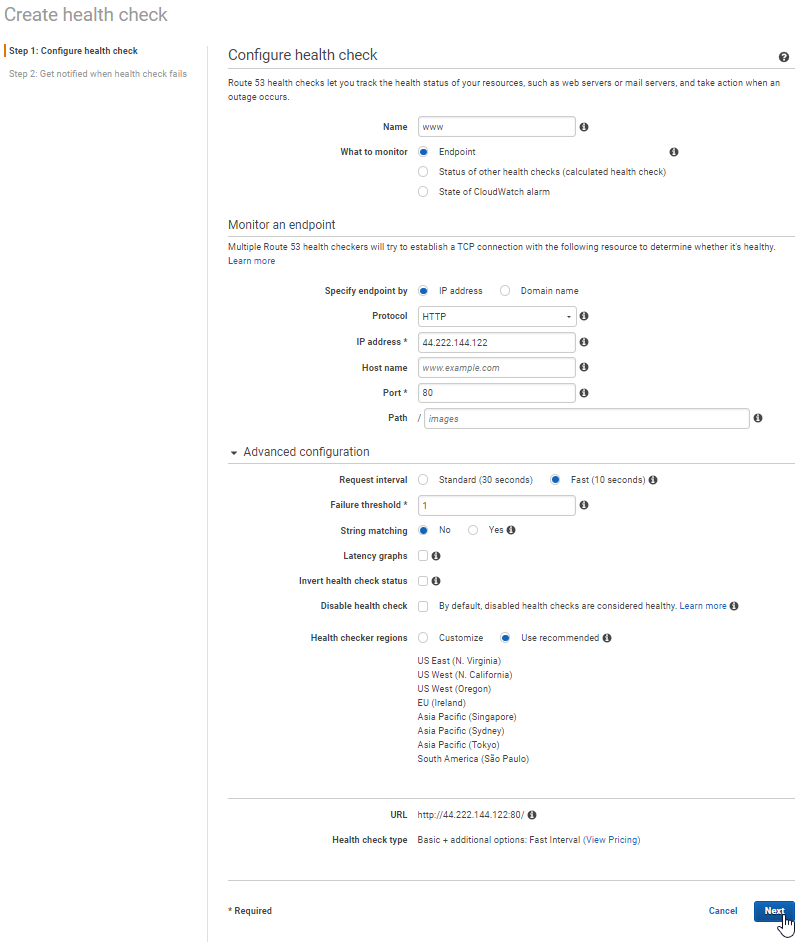
- Health Check 1 for my primary webserver
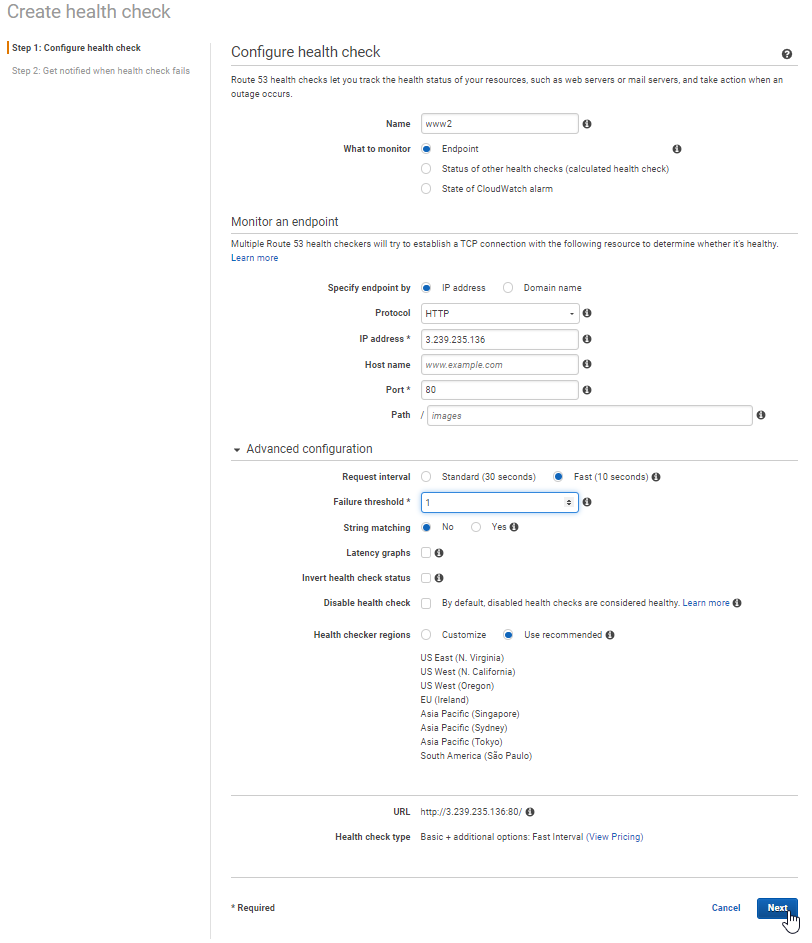
- Health Check 2 for my secondary webserver
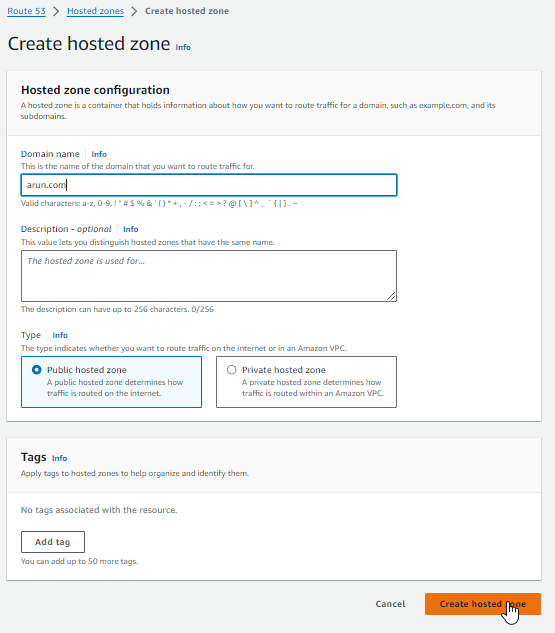
- Route 53 Zone (Private but could be Public) called arun.com
- Route 53 A record with name of www pointing to the public IP address of 44.222.144.122 with a failover routing policy with a primary record type linked to Health Check 1
- Route 53 A record with name of www pointing to the public IP address of 3.239.235.136 with a failover routing policy with a secondary record type linked to Health Check 2
Steps
VPC
- Create VPC
- Create Internet Gateway (IGW) and attach to VPC
- Create public subnets
- Create public route tables with default route to IGW
EC2 – Primary
- Create EC2
- Install Apache
- yum install httpd -y
- Configure index.html
- create file in /var/www/html such that it is distinct
- Start webservice
- systemctl start httpd
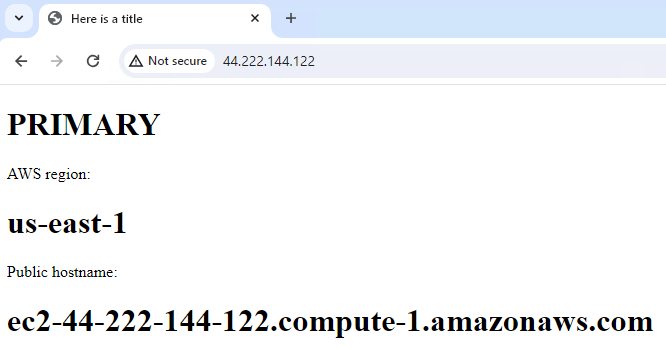
- Browse to public IP address and confirm server is up and listening for http
EC2 – Secondary
- Create EC2
- Install Apache
- yum install httpd -y
- Configure index.html
- create file in /var/www/html such that it is distinct
- Start webservice
- systemctl start httpd
- Browse to public IP address and confirm server is up and listening for http
Route 53
- Create zone
- Create Health Check 1
- Name could be anything you want to label it
- Endpoint monitor
- Protocol: http
- IP address: public IP address for primary server
- Port: what port to monitor
- Create Health Check 2
- Name could be anything you want to label it, but be distinct from the first health check
- Endpoint monitor
- Protocol: http
- IP address: public IP address for secondary server
- Port: what port to monitor
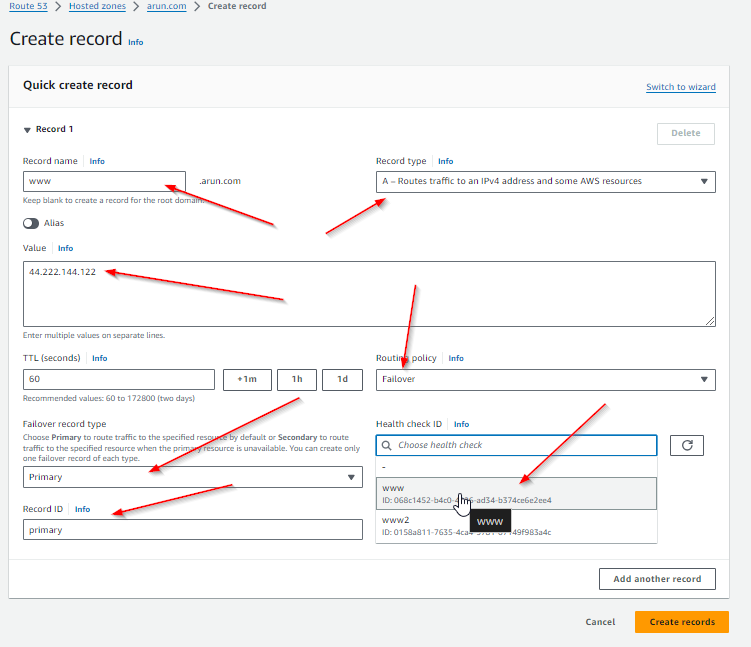
- Create the A Record for Primary
- record name will be the same for both Primary and Secondary (next step)
- record type will be A
- value will be the public IP address for the Primary server
- Routing Policy will be Failover
- Failover record type will be Primary
- Healch check ID will be the health check that was created for the primary server
- Record ID can be anything you want to label it
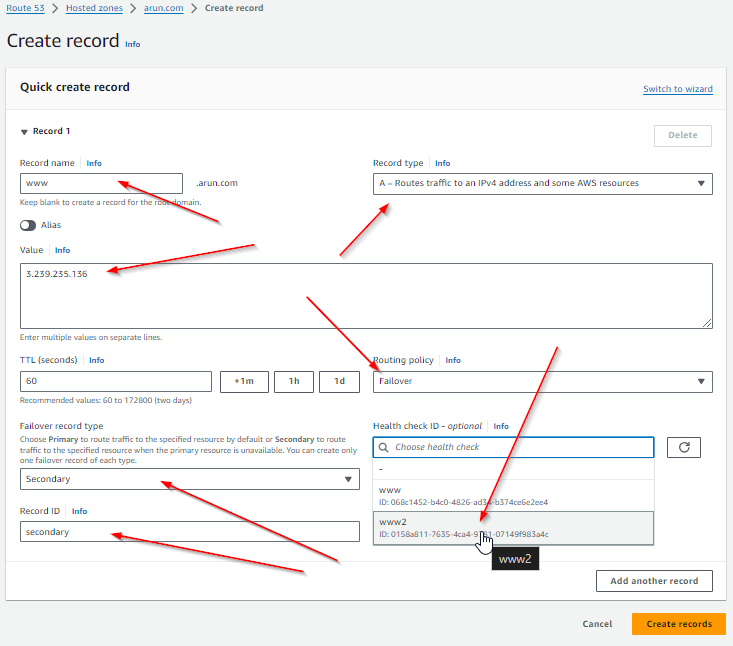
- Create the A record for Secondary
- record name will be the same for both Primary and Secondary (next step)
- record type will be A
- value will be the public IP address for the Primary server
- Routing Policy will be Failover
- Failover record type will be Primary
- Healch check ID will be the health check that was created for the primary server
- Record ID can be anything you want to label i
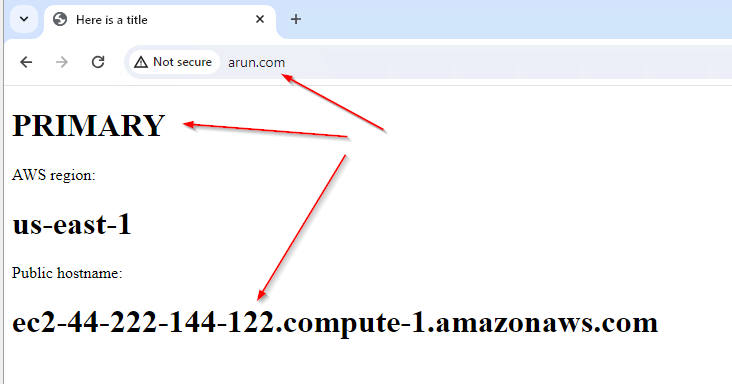
Test – During Non Disaster
- Browse to the A record
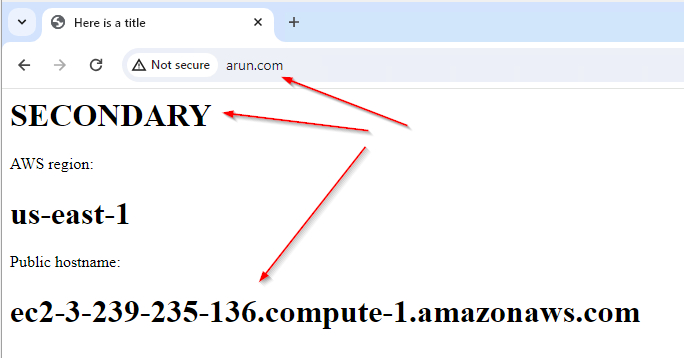
Test – During Disaster
- On primary EC2 stop the Apache service
- systemctl stop httpd
- In Route 53 Health Checks, you will see the primary server health check show Unhealthy

- Browsing to the same A record will show you that the record was flipped to the secondary
Conclusion
In conclusion, AWS Route 53 health checks offer a robust and flexible solution for monitoring the health and performance of your web applications and services. By leveraging Route 53’s ability to perform health checks from multiple locations around the world, you can ensure that your applications are always accessible to your users, regardless of their geographic location. The integration of health checks with DNS failover and routing policies further enhances the resilience and availability of your services, enabling automatic rerouting of traffic away from unhealthy endpoints to ensure uninterrupted service delivery.
Moreover, the customization options available for health checks, including the ability to set thresholds, choose health check intervals, and specify the criteria for determining the health of an endpoint, provide the granularity needed to tailor monitoring to the specific needs of your application. This customization, coupled with the simplicity of setup and the integration with other AWS services, makes Route 53 health checks an invaluable tool in the AWS ecosystem for maintaining the health and performance of your applications.
As businesses continue to rely on the cloud for delivering critical services, the importance of effective health monitoring and failover strategies cannot be overstated. AWS Route 53 health checks not only offer a powerful mechanism for achieving these objectives but also do so in a way that is simple, cost-effective, and seamlessly integrated with the broader AWS platform. Whether you’re running a small website or a large, distributed application, incorporating Route 53 health checks into your operational toolkit can significantly enhance your service reliability, improve user experience, and ultimately contribute to the success of your online presence.